Quite often estimates are needed where there is low-information, but a high-confidence estimate is required. For a lot of engineers, this presents a paradox.
How can I present a high confidence estimate, when I don’t have all the information?
Ironically, this issue is solved fairly easy by noting the difference between high confidence and high accuracy estimate. A high confidence estimate is defined by likelihood that a task will be completed within a given timeframe, while a high accuracy estimate provides a prescribed level of effort to complete the task. This article presents a method of balancing a high confidence estimate balancing analysis effort against accuracy.
This is a refinement on the “Getting Good Estimates” posting from 2011.
The Estimation Model
The basis for this method is captured in the diagram below. The key measures on the diagram are
- Confidence, the likelihood that the task will be completed by a given date (Task will be complete in 15 days at 90% confidence)
- Accuracy, the range of effort for an estimate (Task will be complete in 10-12 days)
- No Earlier Than, absolute minimum effort for a task.

In general, I never accept a naked estimate of a number of days. An estimate of a range will usually imply a confidence level. An estimate of a confidence level may or may not need an indication of accuracy – depending on context for the estimate.
Gaming out the Estimate
As a refinement to the method outlined in Getting Good Estimates, the same technique of calling out numbers can be used to pull out an estimation curve from an engineer. The method follows the same iterative method outlined in Getting Good Estimates By asking the question, “What is the confidence that the task would be complete by date xxx?, you will end up with a results similar to
| Question | Answer |
| What’s the lowest effort for this task? | 2 weeks |
| What’s the likelihood it will task 20 weeks | 100% (Usually said very quickly and confidently) |
| What’s the likelihood it will take 10 weeks | 95% (Usually accompanied a small pause for contemplation) |
| What’s the likelihood it will take 5 weeks | 70% (Usually with a rocking head indicating reasonable confidence) |
| What’s the likelihood it will take 4 weeks | 60% |
| What’s the likelihood it will take 3 weeks | 30% |
| What’s the likelihood it will take 2 weeks | 5% |
That line of questions would yield the following graph.

I could then make the following statements based on that graph.
- The task is unlikely to take less than 2 weeks. (No earlier than)
- The task will likely take between 4 and 8 weeks (50-90% confidence)
- We can be confident that the task will be complete within 8 weeks. (90% confidence)
- Within a project plan, you could apply PERT (O=2, M=4[50%], P=8[50%]) and put in 4.3 weeks
Based on the estimate, I would probably dive into the delta between the 4 and 8 weeks. More succinctly I would ask the engineer, “What could go wrong that would cause the 4 weeks to blow out to 8 weeks?”. Most engineers will have a small list of items that they are concerned about, from code/design quality, familiarity with the subsystem to potentially violating performance or memory constraints. This information is critically important because it kick starts your Risk and Issues list (see a previous post on RAID) for the project. A quick and simply analysis on the likelihood and impact of the risks may highlight an explicit risk mitigation or issue corrective action task that should be added to the project.
I usually do this sort of process on the whiteboard rather than formalizing it in a spreadsheet.
Shaping the Estimate
Within the context of a singular estimate I will usually ask some probing questions in an effort to get more items into the RAID information. After asking the questions, I’ll typically re-shape the curve by walking the estimate confidences again. The typical questions are:
- What could happen that could shift the entire curve to the right (effectively moving the No Earlier Than point)
- What could we do to make the curve more vertical (effectively mitigate risks, challenge assumptions or correct issues)
RAID and High Accuracy Estimates
The number of days on the curve from 50% to 90% is what I am using as my measure of accuracy. So how can we improve accuracy? In general by working the RAID information to Mitigate Risks, Challenge Assumptions, Correct Issues, and Manage Dependencies. Engineers may use terms like “Proof of concept”, “Research the issue”, or “Look at the code” to help drive the RAID. I find it is more enlightening for the engineer to actually call out their unknowns, thereby making it a shared problem that other experts can help resolve.
Now the return on investment for working the RAID information needs to be carefully managed. After a certain point the return on deeper analysis begins to diminish and you just need to call the estimate complete. An analogy I use is getting an electrician to quote on adding a couple of outlets and then having the electrician check the breaker box and trace each circuit through the house. Sure it may make the accuracy of the estimate much higher, but you quickly find that the estimate refinement is eating seriously into the task will take anyway.
The level of accuracy needed for most tasks is a range of 50-100% of the base value. In real terms, I am comfortable with estimates with accuracy of 4-6 weeks, 5-10 days and so on. You throw PERT over those and you have a realistic estimate that will usually be reasonably accurate.
RAID and High Confidence Estimates
The other side of the estimate game deals with high confidence estimates. This is a slightly different kind of estimate that is used in roadmaps where there is insufficient time to determine an estimate with a high level of accuracy. The RAID information is used heavily in this type of estimate, albiet in a different way.
In a high confidence estimate, you are looking for something closer to “No Later Than” rather than “Typical”. A lot of engineers struggle with this sort of estimate since it goes against the natural urge to ‘pull rabbits out of a hat’ with optimistic estimates. Instead you are playing a pessimistic game where an usually high number of risks become realized into issues that need to be dealt with. By baking those realized risks into the estimate you can provide high confidence estimates without a deep level of analysis.
In the context of the Cone of Uncertianty, the high confidence estimate will always be slightly on the pessimistic side. This allows there to be a sufficient hedge against something going wrong.
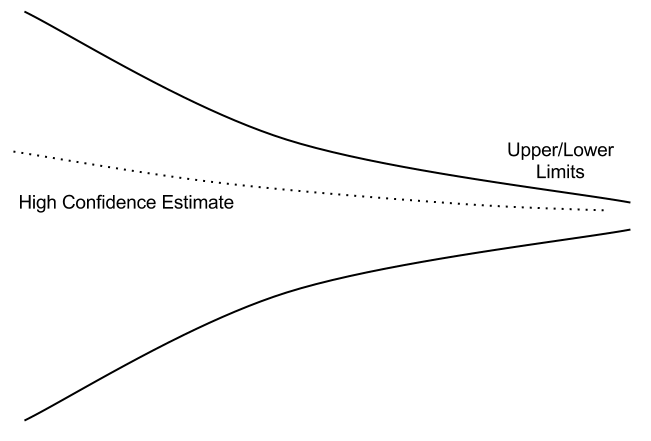
If there is a high likelihood that a risk will become realized or an assumption is incorrect, it is well worth investing a balanced amount of effort to remove those unknowns. It tightens the cone of uncertainty earlier and allows you to converge faster.
Timeboxing and Prototypical Estimates
I usually place a timebox around initial estimates. This forces quick thinking on the engineers side. I try to give them the opportunity to blurt out a series of RAID items to help balance the intrinsic need to give a short estimate and the reality that there are unknowns that will make that short estimate wrong. This timebox will typically be measured in minutes, not hours. Even under the duress of a very small timebox, I find these estimates are usually reasonably accurate, particularly when estimates carry the caveats of risks and assumptions that ultimately are challenged.
There are a few prototypical estimates that I’ve seen engineers give out multiple times. My general interpretation of the estimate, and what refinement steps I usually take. These steps fit into the timebox I describe above.
| Estimate Style | Interpretation | Refinement |
|---|---|---|
| The task will take between 2 days and 2 months | Low accuracy, Low Information | Start with the 2 day estimate and identify RAID items that push to 2 months |
| The task will take up to 3 weeks |
Unknown accuracy, no lower bound | Ask for no-earlier-than estimate, and identify RAID items. |
| The task is about 2 weeks | Likely lower bound, optimistic | Identify RAID items, what could go wrong. |
Agree? Disagree? Have an alternative view or opinion? Leave comments below.
If you are interested in articles on Management, Software Engineering or any other topic of interest, you can contact Matthew at tippettm_@_gmail.com via email, @tippettm on twitter, Matthew Tippett on LinkedIn, +MatthewTippettGplus on Google+ or this blog at https://use-cases.org/.

3 thoughts on “High Confidence/Low Information vs High Accuracy/Low Information Estimates”